Context · Memory · Iteration
ReUX.ai
Turning fragmented product signals into continuous product improvement.
ReUX was built around a simple realization: AI could generate interfaces,but products still lacked shared context, persistent memory,and continuous learning systems needed to improve productswith trust over time.

Independent AI Product Project
0-1 product concept and working prototypeProduct Overview
What is ReUX?
ReUX is an AI-native product iteration system built for what happens after launch. It turns fragmented product signals — from real user behavior, research, feedback, and product changes — into structured insights, agent-ready actions, and verified improvements.
Over time, every validated change compounds into longitudinal product memory, helping teams make better product decisions instead of restarting from scratch.

My Role
I Designed ReUX as a Continuous Product Learning System
I shaped ReUX from product thesis to working prototype — defining the strategy, UX architecture, AI workflow model, and system logic behind a continuous product iteration loop.
Origin Story
ReUX Started Inside a Real Enterprise Migration
After Zeta Global acquired Marigold Loyalty, the challenge was not simply redesigning screens. The platform had accumulated years of fragmented workflows, duplicated logic, inconsistent UX patterns, and disconnected product signals spread across teams and systems.
Kaleido exposed the deeper problem: product teams had signals everywhere, but no shared product memory to understand what changed, why it mattered, or how the system should evolve.
That gap became the starting point for ReUX: a system designed to transform fragmented product signals into shared product context, and shared context into continuous product iteration.
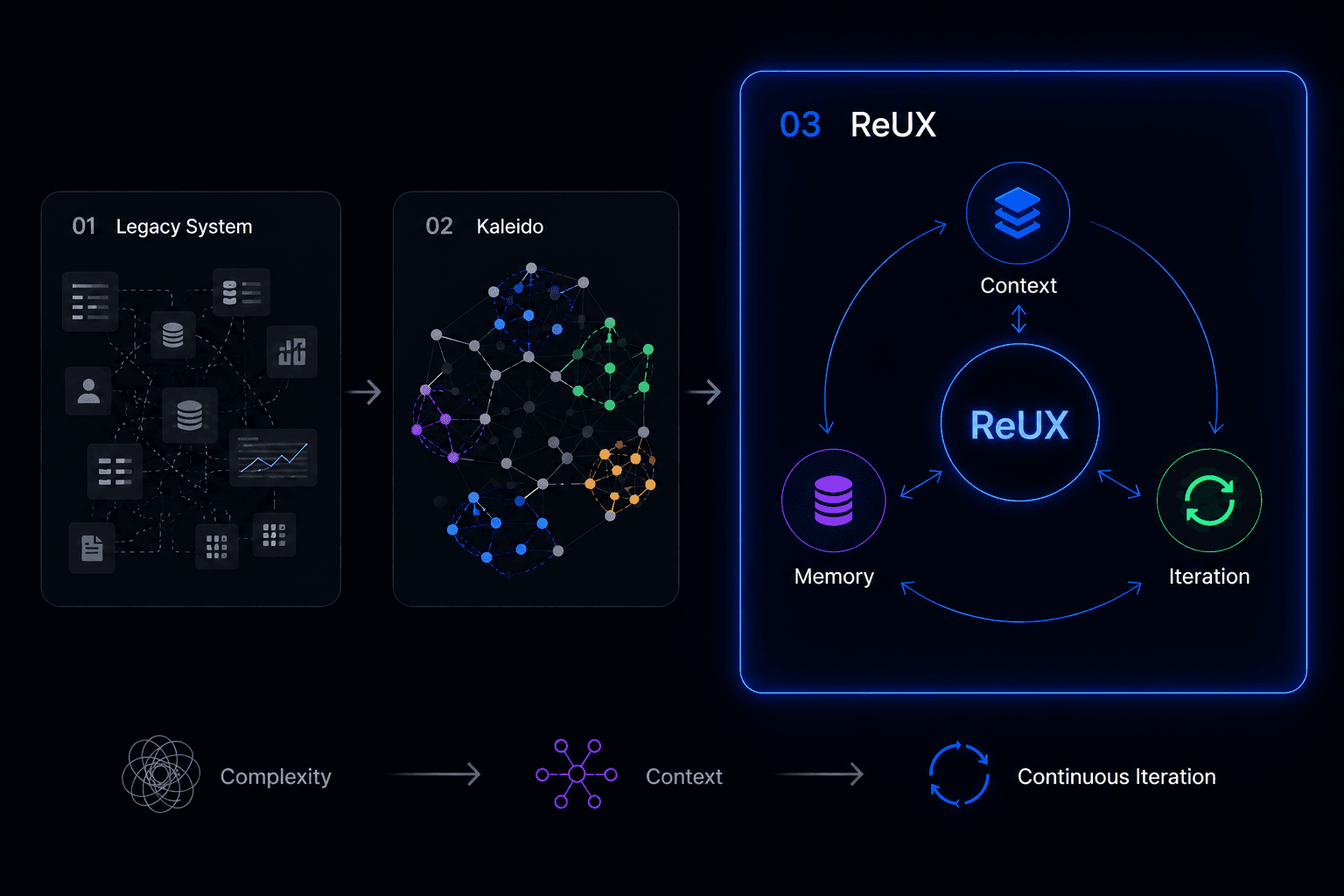
Enterprise Complexity
Large systems became difficult to evolve consistently.
Building Kaleido
I started mapping fragmented workflows and product logic.
The Real Bottleneck
The issue wasn’t generation. It was missing context and memory.
Why ReUX Exists
AI needed a continuous product iteration system.
The Insight
AI Made Shipping Cheap. Context Became the Bottleneck.
Product knowledge lived across disconnected tools, workflows, and teams.
AI could generate outputs, but lacked product understanding and memory.
Teams still relied on manual validation, repeated decisions, and disconnected iteration.
AI execution became cheap. Product context became the moat.

Fragmented signals → shared product context.
MVP Scope
Building the Vision Was Easy. Defining the First Real Loop Was Hard.
ReUX started as a much larger vision: a continuous AI-native product iteration system connecting signals, context, execution, and learning.
But building everything at once would have created complexity before proving value. The danger wasn’t building too little — it was building a system too complex to verify.
The real challenge was defining the smallest loop capable of producing trustworthy product learning.
One Loop Before Scale
A single verified feedback loop mattered more than broad feature coverage.
Context Before Autonomy
Agents without product context create noise, not trustworthy execution.
Verify Before Scaling
Every output needed measurable validation before expanding the system.
Real Workflows Over Demos
The MVP had to work on real products.
What I Chose Not to Build First
Full Autonomous Agents
Too much autonomy without product context would create noise.
Research Automation
Useful, but not enough to prove the full product iteration loop.
Design Generation Tool
Easy to demo, but too close to existing AI UI tools.
Analytics Dashboard
Helpful for visibility, but dashboards alone do not create action.
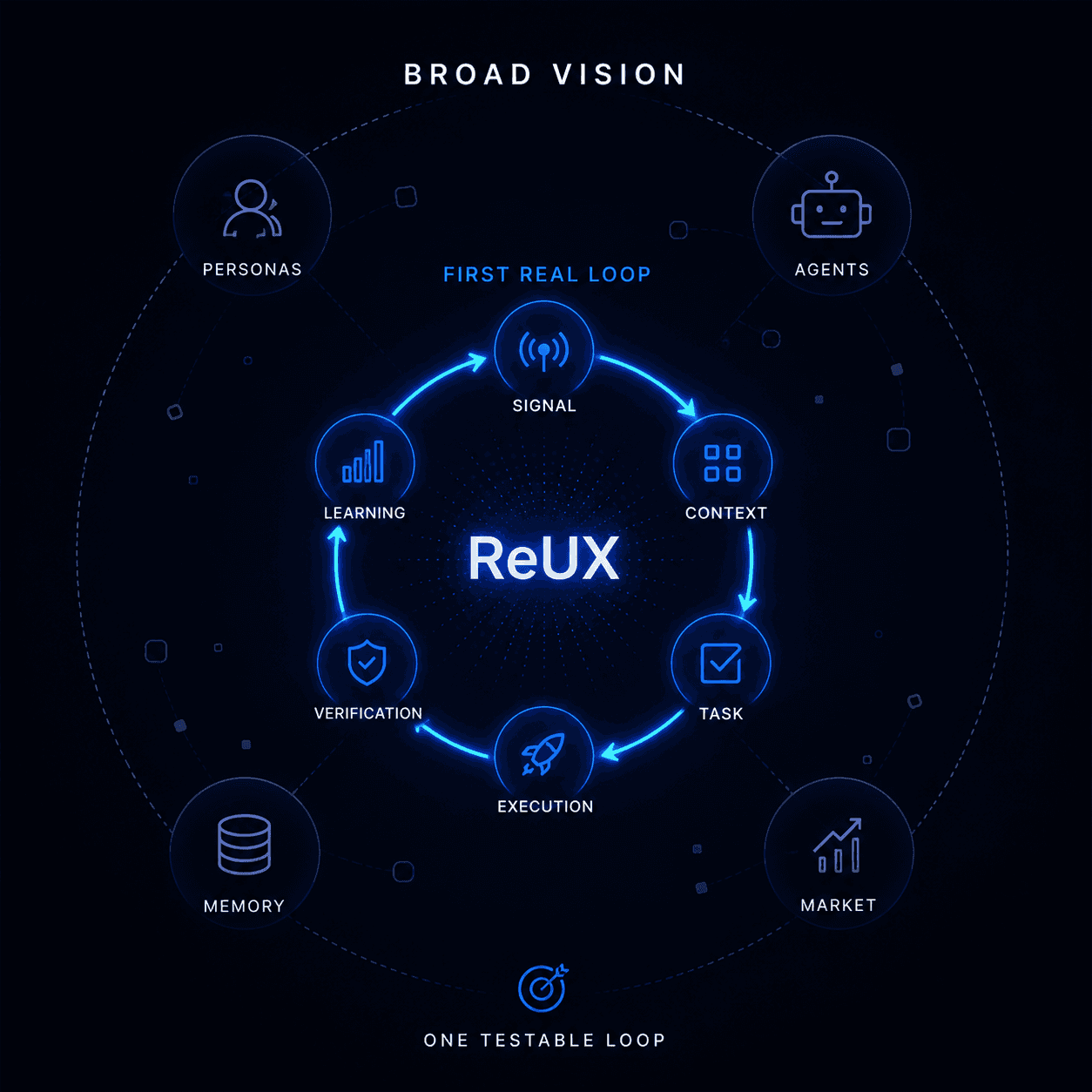
The Decision
I chose to prove one loop first:
Signal → Context → Task → Execution → Verification → Learning
MVP Test Run
Signal → Context → Task → Agent Execution → Verification → Learning
We didn’t ask: “Can AI generate something?”
We asked: “Can the system continuously improve products through verified iteration?”
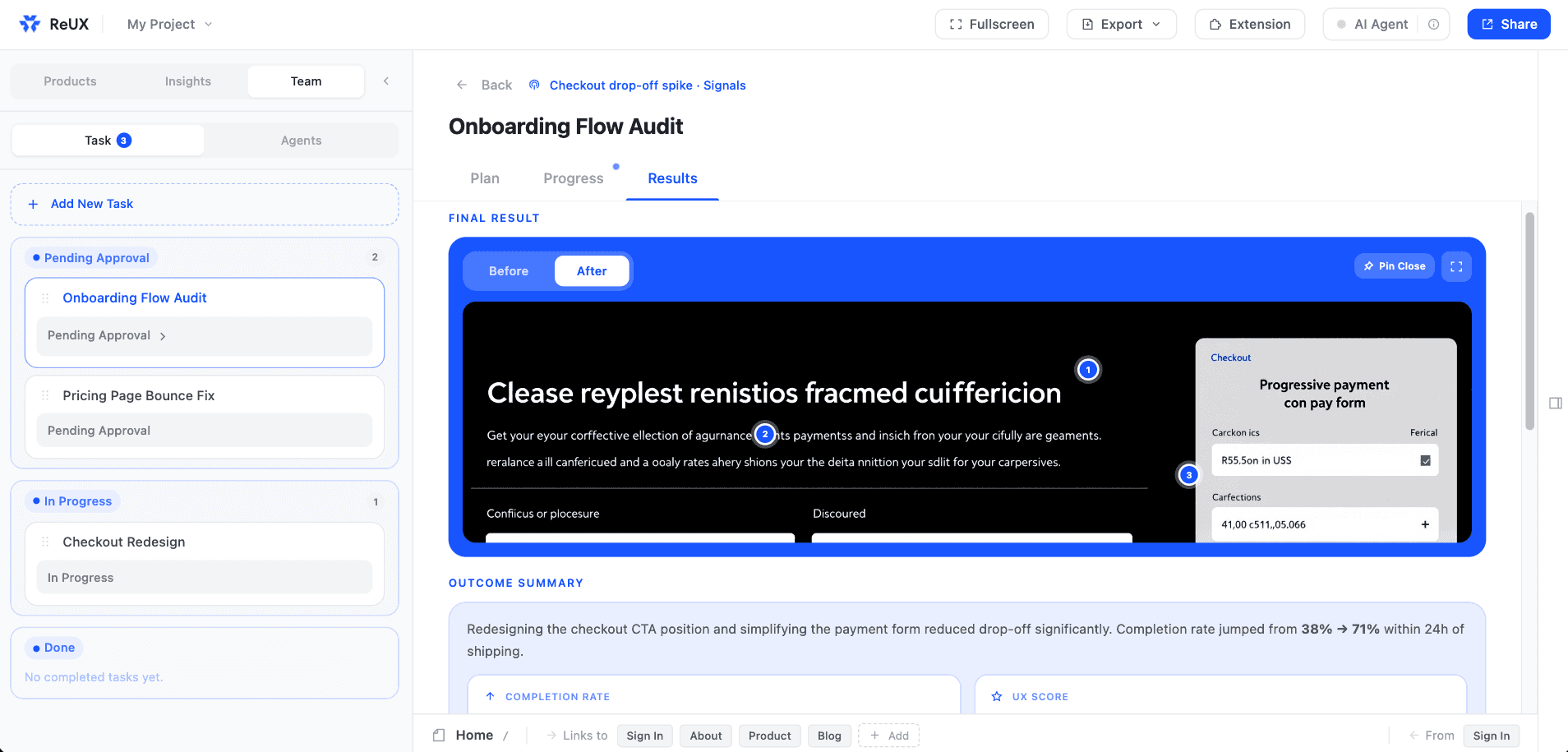
Interactive Product Layer
ReUX Was Designed to Be Tested on Real Products.
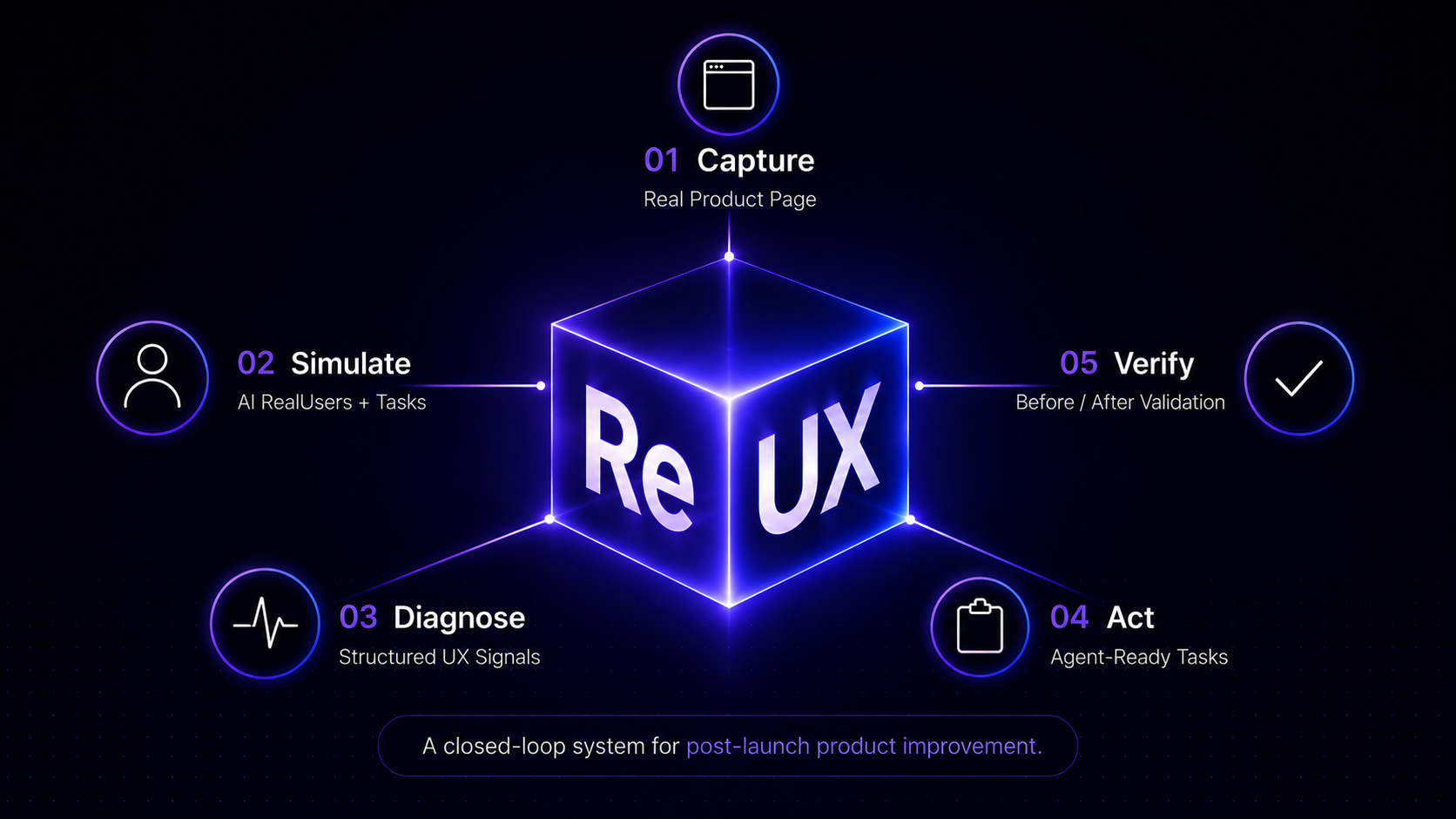
To move beyond static AI demos, ReUX introduced interactive workflows that could operate directly on real product environments. The system included a Chrome extension for live product structure capture, AI-powered personas for behavioral simulation, and workflow testing layers capable of generating signals, tasks, and validation loops from real interfaces.
Instead of presenting isolated concepts, ReUX was designed as something users could actively test, interact with, and learn from.
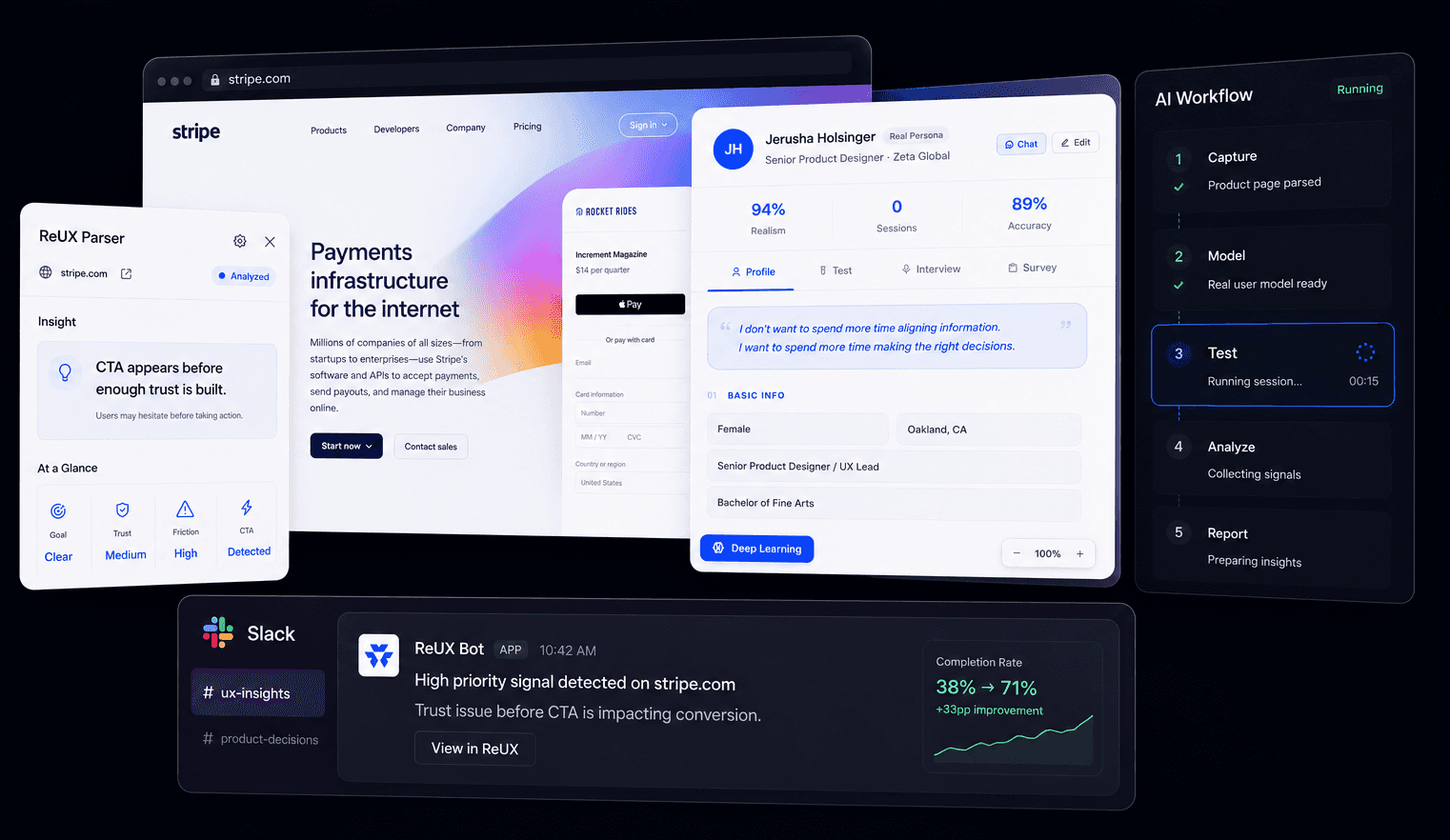
Key Features
01Chrome Extension
02AI Personas / RealUsersLive
03Workflow Testing
04Product Structure Mapping
Capture the Product
Use the extension to read live pages, UI structure, and product context.
Model the User
Create AI RealUsers with goals, behavior patterns, and decision constraints.
Run the Workflow
Let RealUsers interact with product flows and generate signals.
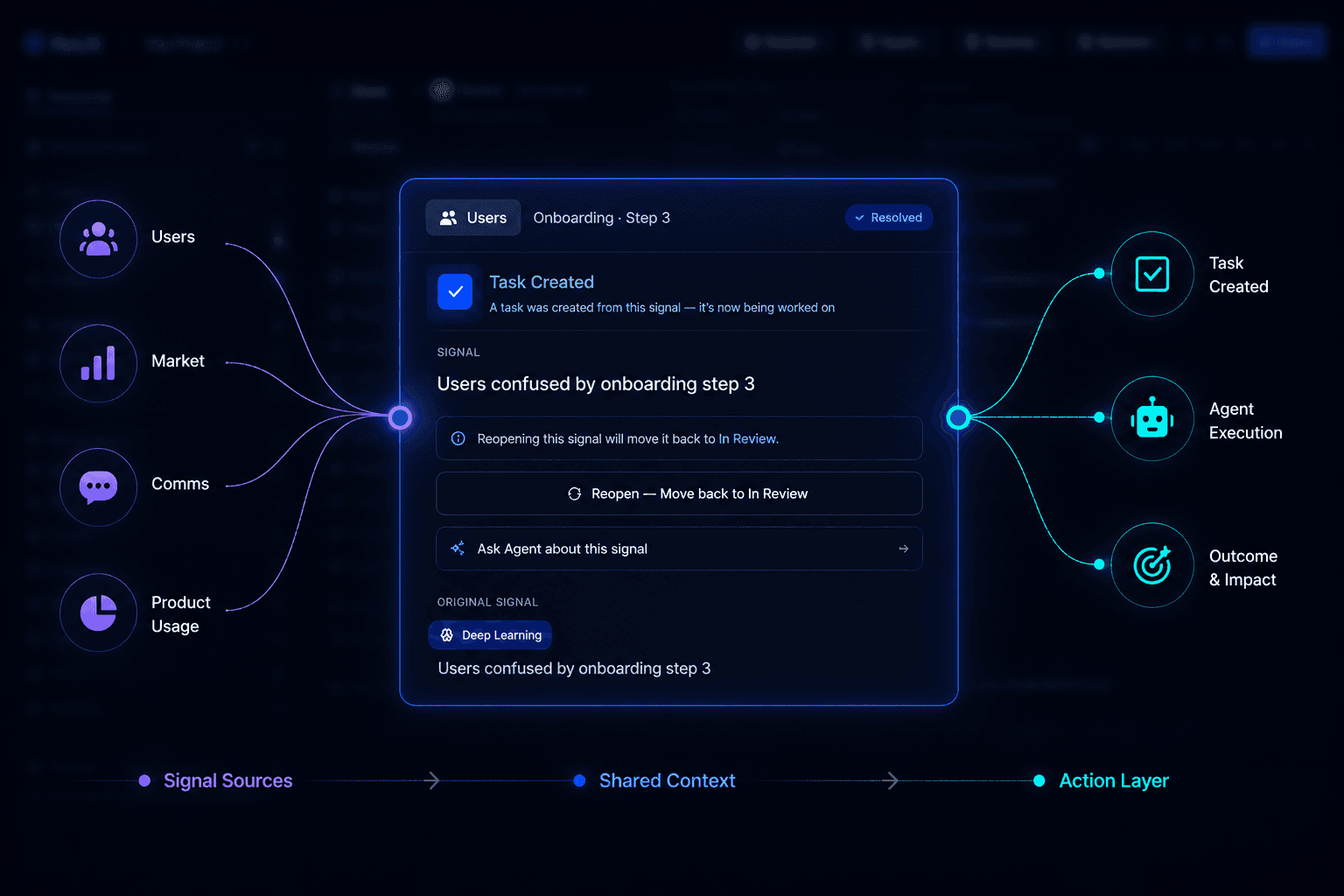
Route Signals
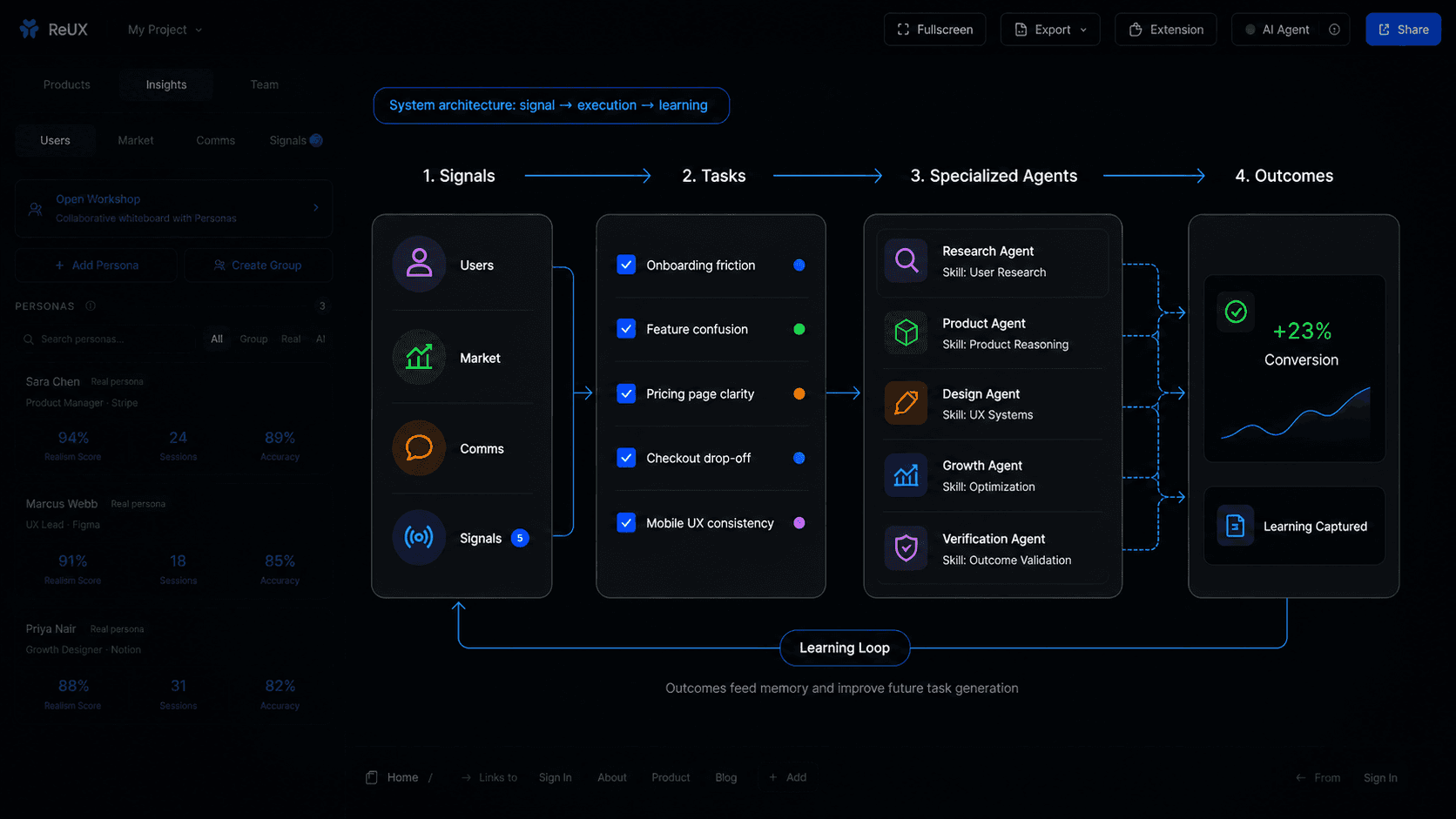
Transform fragmented signals into structured tasks, coordinated workflows, and specialized agent execution tied directly to shared product context.
Verify Outcomes
Validate outcomes, measure iteration impact, and feed verified product learning back into memory for continuous improvement.
Real Product Signals
Products Already Contain Signals Everywhere.
User behavior, support feedback, market shifts, workflow friction, and team discussions already contain signals about what products need next.
The challenge isn’t collecting more data. It’s turning fragmented signals into something teams can actually understand and act on.
Signals are not insights yet.


Shared Product Context
Signals Become Useful Only When Context Connects Them.
ReUX transforms fragmented product signals into shared product understanding by connecting workflows, user behavior, historical decisions, system logic, and organizational knowledge into one continuous context layer.
Instead of isolated dashboards or disconnected AI outputs, teams operate from a shared understanding of how products evolve over time.
Context turns fragmented signals into coordinated product decisions.
Product Memory Layer
Continuous Product Improvement Requires Memory.
Most AI systems generate outputs in isolation. Once a workflow ends, the system forgets what happened, why decisions were made, and how products evolved over time.
ReUX was designed differently.
The system preserves product history, workflow evolution, validation results, signal relationships, and organizational decisions as a continuous product memory layer.
AI without memory cannot continuously improve products.
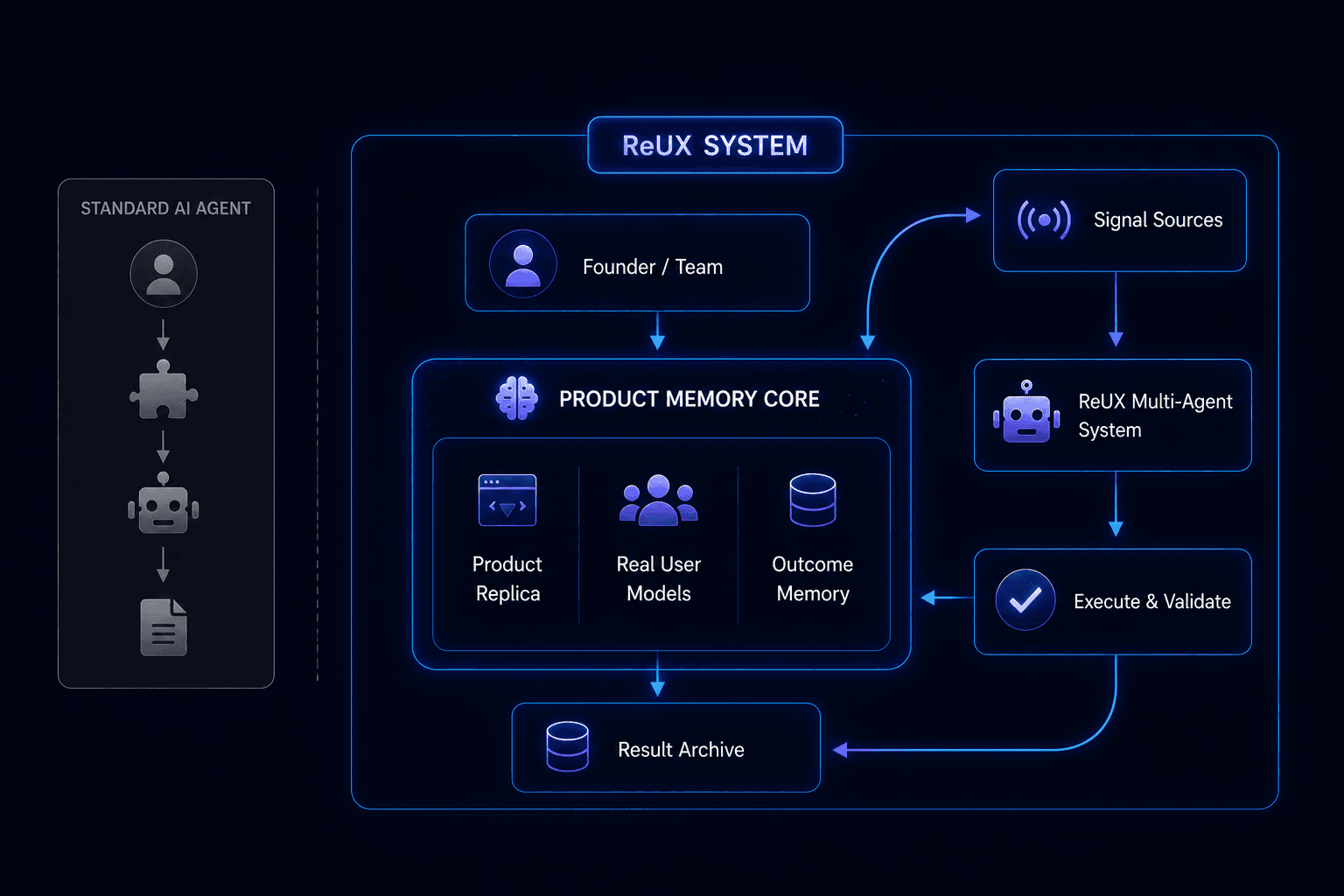
Task & Agent Execution
Shared Context Creates Coordinated Execution.
Once signals become shared context, ReUX transforms them into tasks, workflows, and coordinated agent execution across design, research, engineering, and product operations.
Instead of isolated recommendations, the system creates structured execution paths tied directly to product understanding and verification.
Context becomes execution.
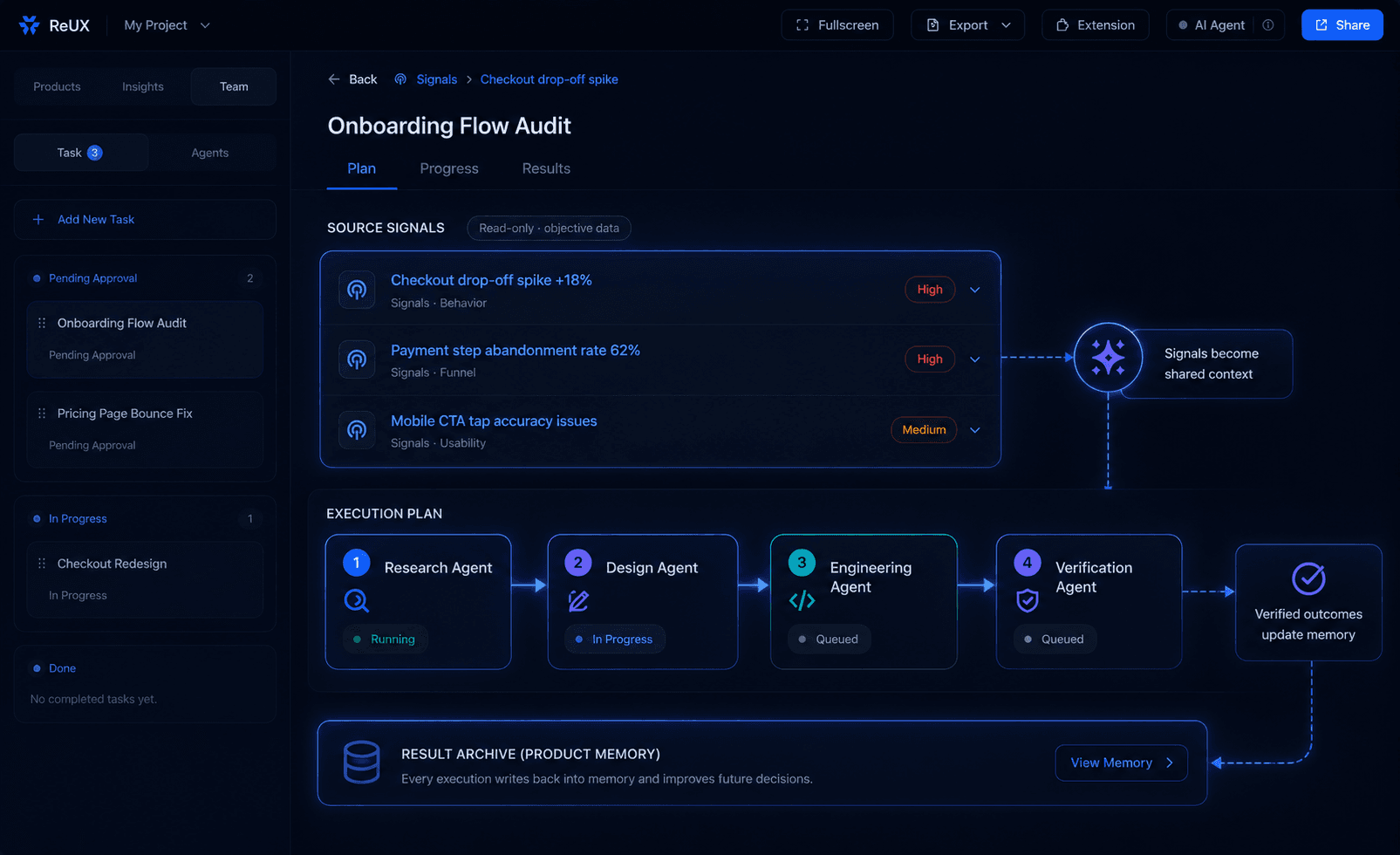
Verification & Learning
Execution Matters Less Than Verified Improvement.
ReUX closes the loop by validating outcomes, tracking iteration impact, and feeding product learning back into the system.
The goal is not simply producing more output. The goal is building systems that continuously improve through verification, learning, and accumulated product memory.
Verified iteration creates trustworthy product learning.
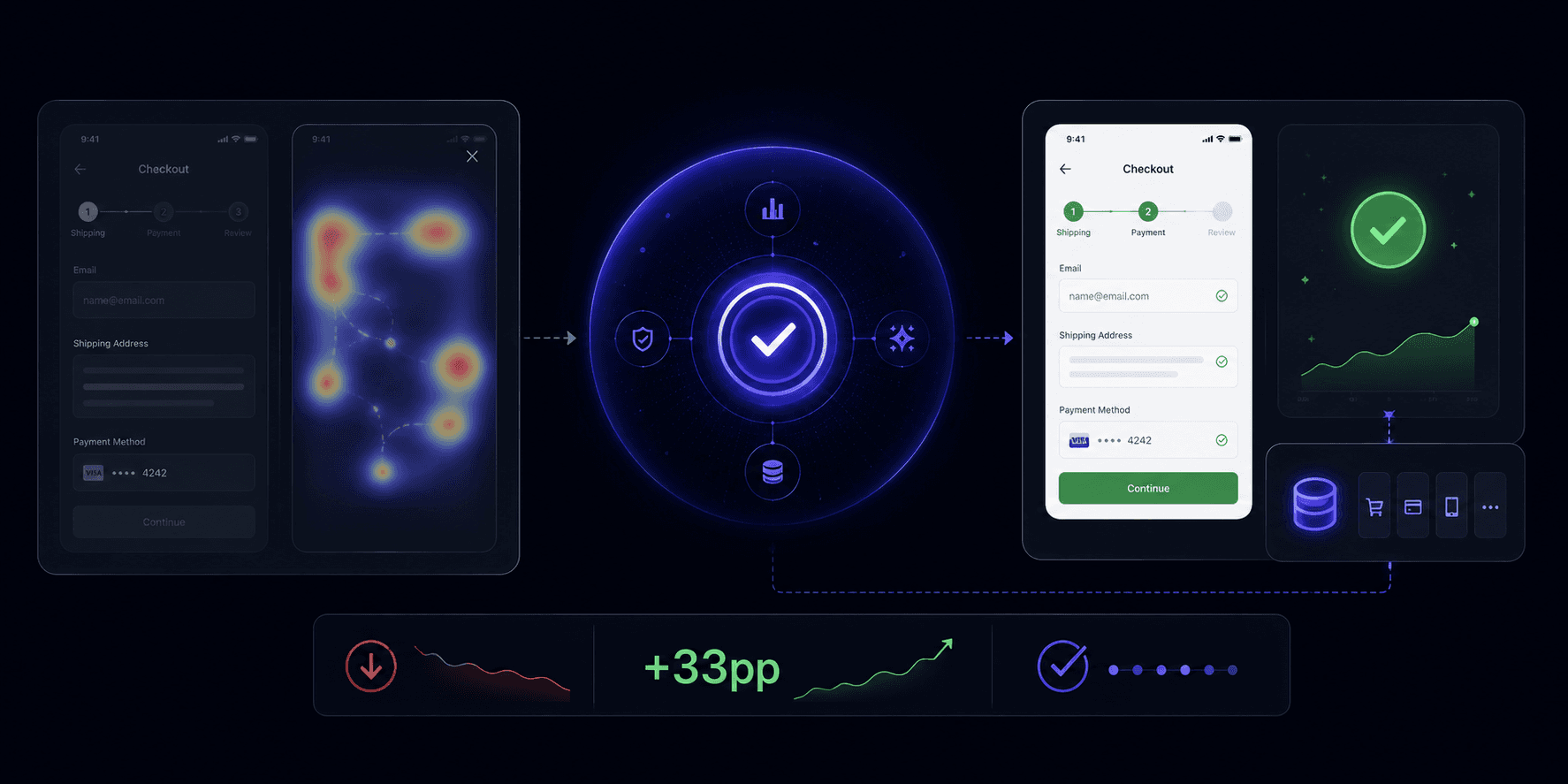
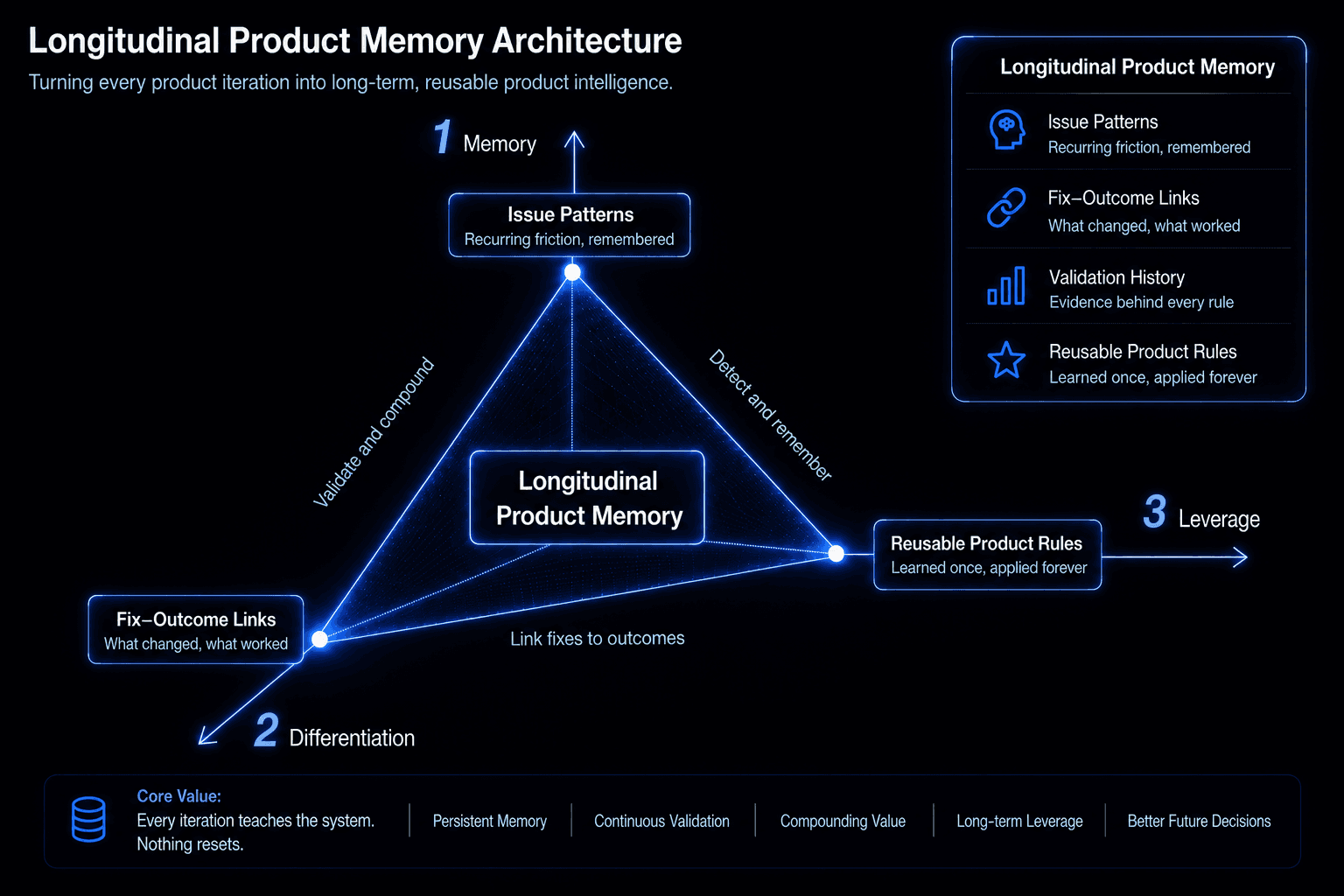
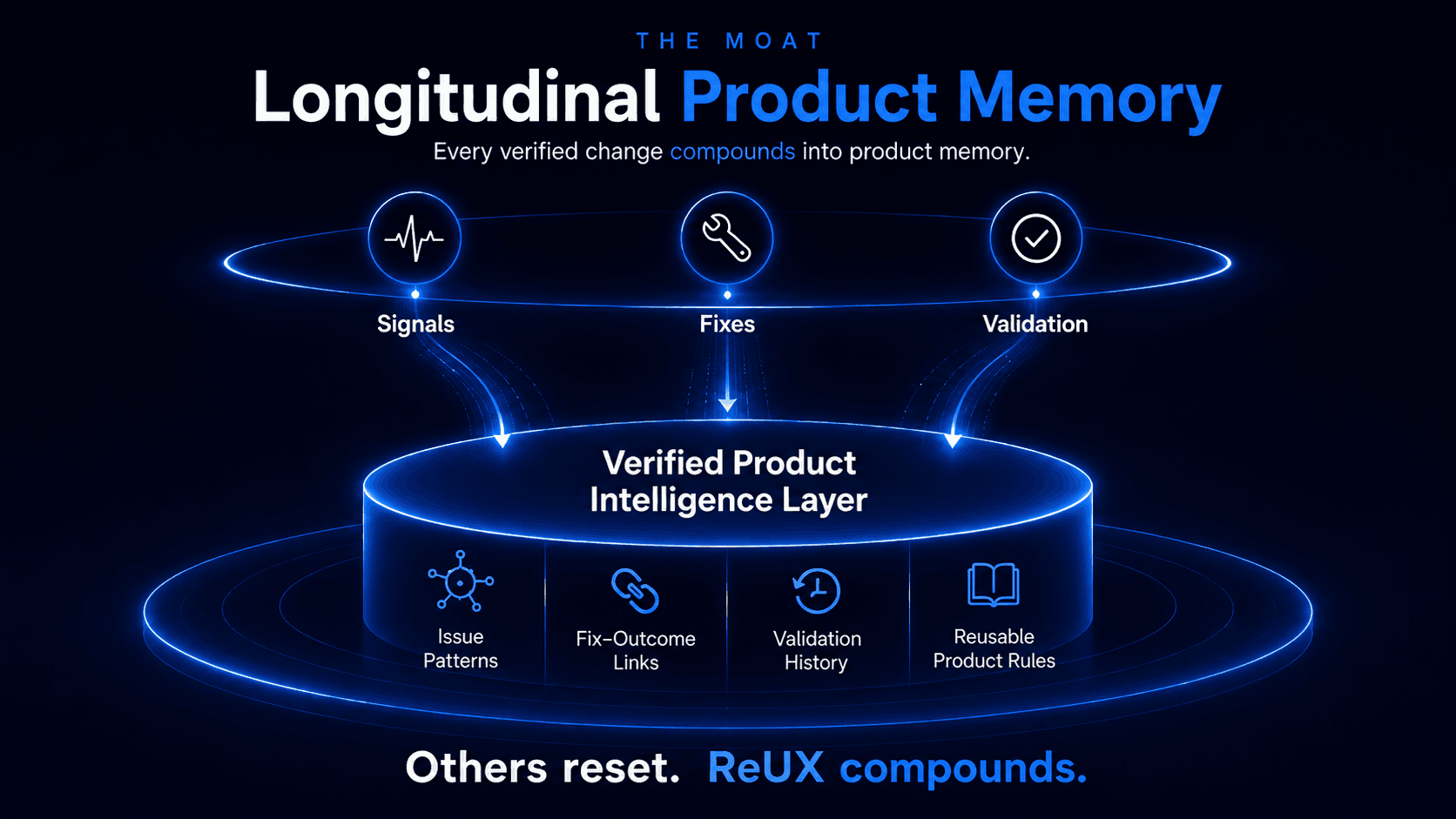
The Moat
ReUX’s moat is a Verified Product Intelligence Layer.
Every iteration connects recurring issue patterns, applied fixes, validation history, and reusable product rules into longitudinal product memory.
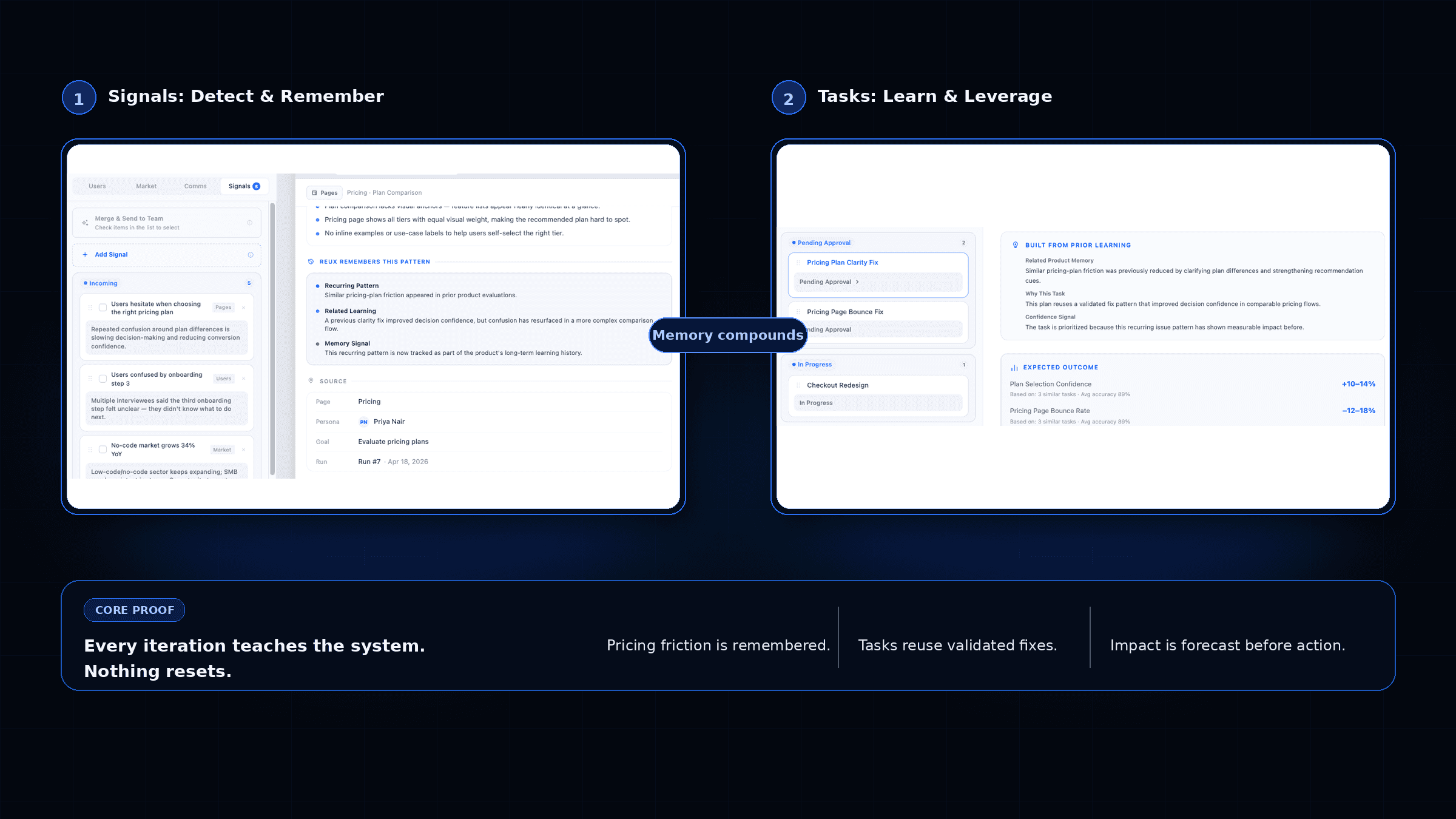
This is what memory looks like in a real product.
Signal→Memory→TaskThe loop closes automatically.
Final Reflection
AI Made Shipping Cheap. Product Context Became the Advantage.
The future advantage will not come from generating more interfaces or automating more screens.
It will come from helping systems understand products, coordinate decisions, preserve organizational memory, and continuously improve after launch.
That is the future ReUX was designed for.
Explore ReUX